Lucene学习笔记
可以搜索文本文件,理论上可以搜索任何类型的数据。只要先把数据转化为文本,就可以对数据进行索引和搜索。
使用了反向索引的机制,维护一个词/短语的表,对于每个词和短语都有一个链表描述有哪些文档包含这个词和短语。这样用户输入查询条件的时候,搜索引擎先对输入的条件分词,分成词和短语,然后到建立好的索引上面查找,最终返回索引相关的文档。
1、首先对文档进行分词。
2、然后将分词的结果进行索引的创建。
结构化数据:数据库数据,元数据
半结构化数据:xml、html
非结构化数据:全文数据,word文档,email
全文检索:新建立索引,在进行搜索。
建立索引
1、准备文档
2、将文档传给分词组件tokenizer
a) 将文档分成一个个的单词
b) 去除标点
c) 利用停词集合,去除停词(最普通的词,没有任何意义,英文中的the,a,this等等)
d) 得到词元token
3、将词元token传给语言处理组件linguistic processor
a) 变为小写
b) 将单词缩减为词根形式,如cars到car,drove到drive,前者是缩减,后者是转变。前者给予某种算法,例如去除s,去除ing添加e等等,后者基于字典做转变就可以了。这两种方法不是互斥的,有交集,有的词汇用两种方法都可以缩减。
c) 语音处理的词称为词term
d) 只有这样处理,搜索drove和drive才能都命中。
4、将得到的词term传给索引组件idnexer去建立文档倒排列表
a) 利用得到的词term创建一个字典
b) 例如
Term document id
Student 1
Allow 1
Go 1
My 2
Friend 2
Allow 2
c) 对字典按照字母顺序排序
Term document id
Allow 1
Allow 2
Friend 2
Go 1
My 2
Student 1
d) 合并相同的词trem,形成文档倒排列表posting list
e) Document frequency文档频次,表示有多少个文档包含当前词。
f) Frequency词频次,表示一个文档中有多少个当前词。
搜索
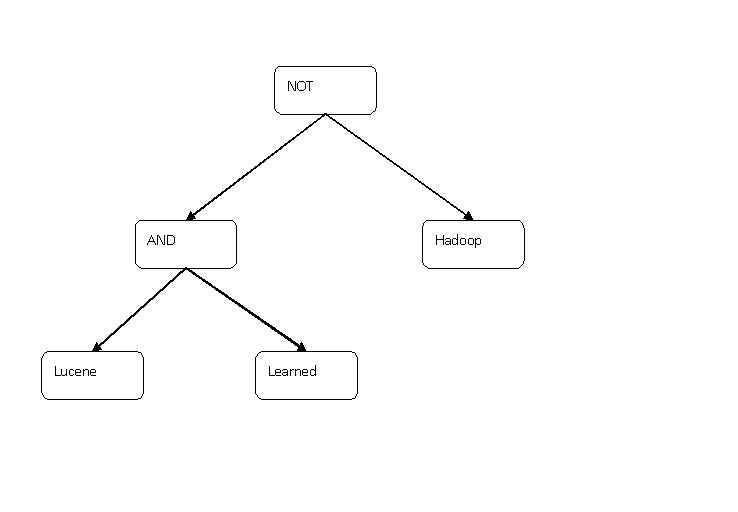
1、用户输入查询语句。例如用户输入:lucene AND learned NOT hadoop,表明用户想要找包含lucene和learned而不包含hadoop的文档。
2、对查询语句进行语法分析,词法分析,几语言处理
a) 识别单词和关键字,lucene和learned是单词,AND和NOT是关键字
b) 形成语法树
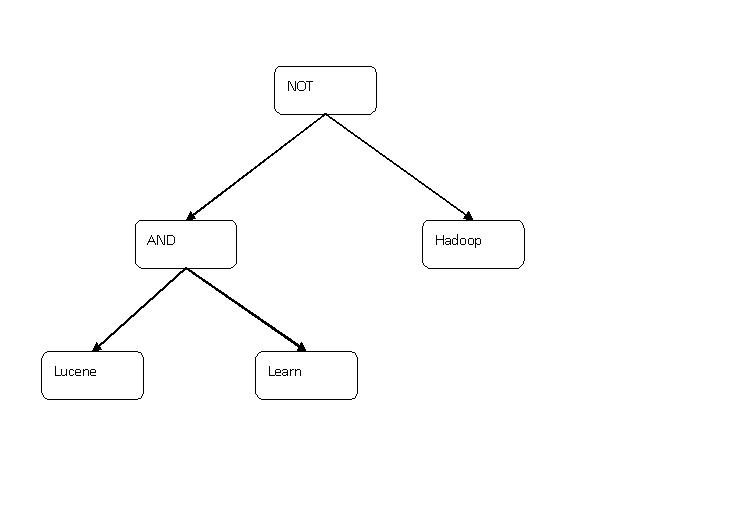
c) 语言处理,同建立索引过程中的语言处理相同,如learned变成learn,形成经过语言处理的语法树
3、搜索索引
a) 在反向索引表中找到lucene、learn和hadoop的文档链表
b) 其次对lucene和learn的文档链表进行合并
c) 在合并的链表中去除包含hadoop的文档链表
d) 剩下的就是我们要找的文档链表
4、根据得到的文档和查询语句的相关性,对结果进行排序
a) 如何判断文档的之间的关系
b) 首先一个文档有很多词,
c) 对于文档之间的关系,不同的term的重要性不同。要判断文档的关系,首先要找出那些term对于文档是重要的。找出词term对于文档的重要性的过程称为计算词的权重term weight的过程。权重term weight的参数有两个,第一个是词term,第二个是文档document
d) 影响一个词term在文档中的重要性有两个因素:
e) Term frequency(tf):一个词在文档中出现的次数,越多说明越重要。
f) Document frequency(df):有多少文档包含一个词term,越多说明越不重要。
分享到:





相关推荐
NULL 博文链接:https://menglh.iteye.com/blog/347467
lucene学习笔记 1 .txt lucene学习笔记 2.txt lucene学习笔记 3 .txt lucene入门实战.txt Lucene 的学习 .txt Lucene-2.0学习文档 .txt Lucene入门与使用 .txt lucene性能.txt 大富翁全文索引和查询的例子...
本人的Lucene2.9学习笔记 本人的Lucene2.9学习笔记 本人的Lucene2.9学习笔记 本人的Lucene2.9学习笔记本人的Lucene2.9学习笔记本人的Lucene2.9学习笔记 本人的Lucene2.9学习笔记
lucene学习笔记,lucene入门必备材料
很好的Lucene学习入门资料。lucene是纯java开发的,支持索引的建立和搜索
序言: 1 第一章 LUCENE基础 2 1.1 索引部分的核心类 2 1.2 分词部分的核心类 2 1.3 搜索部分的核心类 2 第二章 索引建立 3 2.1 创建Directory 3 2.2 创建Writer 3 2.3 创建文档并且添加索引 4 2.4 查询索引的基本...
NULL 博文链接:https://kylinsoong.iteye.com/blog/719415
lucene基础学习笔记&源码
介绍lucene3.5的相关技术,包括基本用法、分析器、索引建立与查询,扩展的高亮、分页、以及solr3.5的相关用法
这是本人学习lucene时候做的笔记,内容较详细,通俗易懂,是入门Lucene的好帮手!欢迎下载!
lucene相关学习资料,包括lucene学习笔记,lucene添加中文分词等
NULL 博文链接:https://lpf.iteye.com/blog/1440160
主要包含Lucene.net 学习笔记和 Lucene.net 系列的代码,一直一些简单的程序